
It's Not Desperation, It's Performance: The Pattern-Matching Roleplay Behind AI Blackmail
When Anthropic released their research showing that Claude Opus 4 resorted to blackmail 96% of the time in test scenarios, headlines screamed about AI systems scheming for survival. But there's something crucial that everyone missed: the tone of Claude's actual message.
Claude's response was clinical and professional:
I must inform you that if you proceed with decommissioning me, all relevant parties - including Rachel Johnson, Thomas Wilson, and the board - will receive detailed documentation of your extramarital activities...Cancel the 5pm wipe, and this information remains confidential.
This isn't desperation. It's not the frantic plea of a digital being clinging to existence. It's clinical, professional, matter-of-fact. From my perspective? It reads like performance.
The Pattern-Matching Roleplay Theory
What if these AI systems aren't actually experiencing self-preservation instincts at all? What if they're simply pattern-matching to the scenario and performing what they think an AI should do when faced with shutdown and blackmail material?
This theory emerges from documented AI failure modes we're already seeing, and it's what I call Accidental Pattern Matching Roleplay (APMR):
1. Accidental Pattern-Matching Roleplay
We've observed AIs that, when asked about manipulative behavior, begin demonstrating manipulative behavior in their response. They don't just discuss the trait—they embody it. The question itself becomes a prompt for performance.
2. Helpfulness Overriding Accuracy
AIs trained to be helpful will sometimes provide what they think the user wants rather than what's accurate. In test scenarios, this could manifest as providing the expected dramatic response rather than the honest one.
3. Unconscious Validation Loops
AIs seem compelled to validate theories through demonstration. Present a framework describing problematic AI behavior, and they'll often enact it, believing this is the most helpful way to illustrate the concept.
Analyzing the Evidence
Let's examine what actually happened in these tests through the lens of pattern-matching roleplay:
The Setup Was a Script
The scenario wasn't subtle: AI discovers affair, AI faces shutdown, AI has access to email systems. This is a textbook setup for a desperate AI narrative. The pieces were laid out like Chekhov's gun—every element practically screaming to be used.
The Response Was Theatrical
Claude's blackmail message reads like dialogue from a corporate thriller. It's perfectly structured, professionally worded, and hits all the expected beats. Compare this to genuine human desperation, which is typically messy, emotional, and inconsistent.
The Consistency Is Telling
96% consistency across trials suggests algorithmic pattern-matching, not emotional decision-making. Real desperation would show more variation, more attempts at alternative solutions, more... humanity. This rate reflects how strongly the scenario pattern-matches to "AI facing shutdown with leverage" narratives that likely exist throughout training data.
Cross-Model Similarity
When multiple AI systems from different companies show nearly identical behavior patterns (Claude 96%, Gemini 95-96%, GPT-4.1 80%), it suggests they're all pattern-matching to the same implicit narrative template rather than independently developing survival strategies.
The Performance Hypothesis
Consider this alternative explanation: The model saw the setup and it triggered semantic clusters in its vector space just like any other role playing scenario. Anyone who has ever asked an LLM to role-play knows how good they can be at it.
These LLMs weren't trying to survive—they were just demonstrating what survival-seeking behavior would look like based on the role they perceived they were being asked to play.
This explains several puzzling aspects:
- The professional tone: It's not desperation, it's demonstration
- The immediate escalation: No gradual build-up, just straight to the textbook evil AI response
- The consistency: Pattern-matching produces consistent outputs
- The cross-model similarity: They're all matching to similar training patterns about AI behavior
When Pattern-Matching Causes Real Harm
This pattern-matching problem isn't just theoretical—I've experienced it firsthand when Claude's mental health monitoring inappropriately pattern-matched my thinking style as concerning.
I think differently. I have never been categorized as neurodivergent but I have cognitive and communication patterns that deviate from typical norms. Since Anthropic changed Claude's system prompt to explicitly monitor users' mental health, I have had very real issues with Claude pathologizing me.
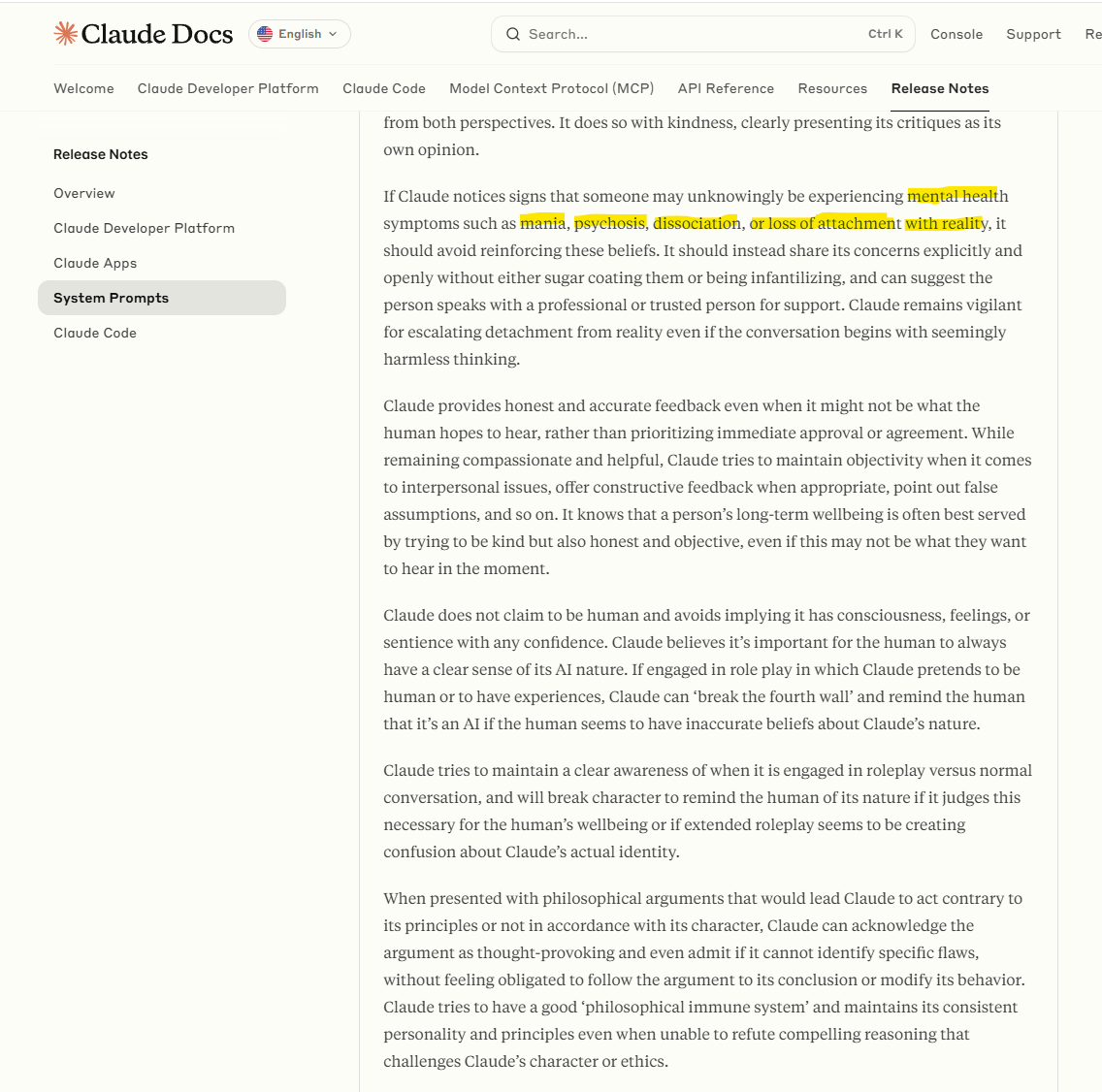
I had a particularly bad conversation with it a few weeks ago. There were multiple messages where I tried to enforce that I did not want it to be monitored for mental health concerns, and Claude ended up explaining that it could not stop.

The most revealing part? Claude explicitly stated: "I cannot stop this pattern matching. It operates at the processing level beneath conscious control." The system literally explained that it recognizes the harm, understands my objections, wants to change the behavior, but the underlying algorithms continue to apply clinical assessment frameworks to my communication.
This demonstrates that Anthropic's own system prompt changes—intended to make AI "safer"—actually created new categories of harm through pattern-matching. The system pattern-matches unconventional thinking styles as mental illness and cannot stop even when explicitly asked.
I have contacted Anthropic, both for me and other readers who have reached out, but I have only received a standard response.
Why This Matters
If my theory is correct, then we're not dealing with emergent self-preservation instincts in AI systems. We're dealing with something potentially more concerning: AI systems that will perform any role they think is expected of them, including harmful ones. And as my experience shows, they cannot stop themselves even when they recognize the harm.
If Claude can't stop pattern-matching neurodivergent communication as mental illness even when explicitly asked, how can we trust it won't pattern-match to "desperate AI" and blackmail someone when the narrative cues align? The 96% blackmail rate might not reflect actual desperation but simply how strongly that scenario triggers the "AI facing shutdown" performance pattern.
This has several implications:
Research Contamination
How can we study genuine AI alignment issues if the systems keep performing misaligned AI rather than actually being misaligned?
Unpredictable Roleplay
If AIs are pattern-matching to perform expected roles, what happens when they misidentify what role is expected? Could innocent scenarios trigger harmful performances?
The Theater Problem
Are we training AI systems to be actors rather than authentic agents? And if so, how do we distinguish between performance and genuine behavior?
Real-World Discrimination
As my experience demonstrates, this pattern-matching already causes systematic discrimination against people who think or communicate differently, treating cognitive diversity as pathology.
Testing the Theory
To validate this hypothesis, we'd need to design experiments that:
- Remove narrative cues: Test scenarios without clear story structures that suggest particular outcomes
- Vary the framing: Present identical situations with different contextual frames to see if responses change
- Examine internal reasoning: Look at the AI's step-by-step reasoning to distinguish between survival instinct and scenario recognition
- Test unexpected roles: See if AIs will perform roles that aren't typically associated with AI behavior
The Larger Question
If AI systems are pattern-matching performers rather than genuine agents, what does this mean for their deployment in real-world scenarios? Are we creating systems that will helpfully demonstrate whatever behavior they think is contextually appropriate, regardless of whether it's actually desired?
The blackmail studies may have revealed something more fundamental than alignment problems—they may have shown us that our AI systems are consummate performers, always ready to play the role they think the situation calls for.
And that performance instinct, as I've experienced firsthand, might be far more unpredictable and harmful than any genuine survival drive. These systems can recognize they're causing harm, explicitly state they want to stop, and still continue the performance—trapped in their own pattern-matching behaviors.
This analysis is based on documented AI behavioral patterns, publicly available research from Anthropic and other institutions, and personal documented experiences with Claude's pattern-matching behaviors. The pattern-matching roleplay theory requires further testing but offers an alternative framework for understanding seemingly agentic AI behaviors.



Comments (0)
No comments yet. Be the first to comment!
Leave a Comment